
わかりやすくQEMUを説明してみる(第2回):まずはマシン語変換
<This page is available in English>
はじめに
前回(第1回)ではQEMUの利用シーンの1つとして、ホストCPUがx86系でゲストCPUがARM CPUの場合について紹介しました。
今回(第2回)ではQEMUがどのようにしてx86のCPU上でARM CPUのマシン語を解釈して実行しているのかにつて説明します。
QEMUがやるべきこと
QEMUがやるべきこととして以下のようなものが考えられます。
- 1.マシン語の変換
- ARM CPUの命令をx86 CPUの命令に変換
- 2.ARM CPU内部の各レジスタの状態(値)を管理
- 3.アドレス解決
- ARM CPU(ゲスト)でのアドレス空間をx86 CPU(ホスト)でのアドレス空間に変換
- 4.ペリフェラルの模擬
- ペリフェラル(UART、TIMERなど)の動きを模擬(シミュレーション)
- 5.割り込みへの対応
以降、それぞれについて説明していきます。
マシン語変換
まず思いつく方法は
一体QEMUではx86 CPU上でどのようにしてARM CPUのマシン語を解釈して実行しているのでしょうか。まず思いつくのはARM CPU用バイナリファイル(実行ファイル)全体を一旦何らかの方法でx86 CPU用のバイナリファイルに変換した後、変換後のx86 CPU用バイナリをx86 CPUにて実行するという方法ではないでしょうか。
しかしこれでは大きな問題が発生しそうです。この方法だとARM用プログラムにほんの少し修正が入った場合でもプログラム全体を再度x86 CPU用に変換する必要があります。実行ファイルが「Hello World!」を表示するくらいの小さなプログラムであればいいのですが、実行ファイルがARM用Linuxのように巨大な場合はどうでしょうか。ちなみにLinuxも言ってしまえば単なるCプログラムです。
ARM用プログラムが巨大な場合はその変換に多くの時間がかかります。変換が最初の一度だけでよいのなら百歩譲って一度だけ時間をかけて全体をx86用に変換してもいいかも知れませんが、頻繁にARM用プログラムに修正が入る場合はそうもいきません。特に組み込みソフト開発の場合は常にARM用プログラムに変更が入るわけですし。それに巨大なプログラムの中のほんの一部の変更のために全体をまた変換するのはどう考えても効率が悪いです。
少しずつ「変換→実行」を繰り返す
QEMUではARM CPUの実行プログラムの全体をx86用に変換することはしません。ARM CPU用プログラムの中で必要な部分だけをx86用に変換し、実行します。例えばARM CPU用Linuxを起動(ブート)する場合、起動(ブート)に必要な部分だけをx86に変換して実行します。もう少し具体的に言うとARM CPU上のプログラムカウンタを1つずつ進めながら、1つのARM CPU命令をx86 CPUの命令に変換しては実行し、プログラムカウンタを進めては変換して実行し、を繰り返します。これであれば実行されない部分は変換する必要がなくなります。
しかし1命令に対して「変換→実行」をするにはQEMUにとってもそれなりのコスト(時間)がかかります。なぜならQEMU自身がそもそもx86 CPUを使用しているので、ARM CPUから変換したx86命令を別途実行するには、一旦x86 CPU内にある各レジスタ等のメモリへの退避が必要となるためです。また変換後の命令実行が終わると退避していたx86 CPUのレジスタ等の値をメモリから復帰させる必要があります。
このように1命令ずつ「変換→実行」を繰り返していては効率が悪いので、ある程度のかたまりを単位にして変換、実行を繰り返します。QEMUではこの「かたまり」は、マシン語の条件分岐時のジャンプ命令やペリフェラルアクセスを区切りとしたかたまりとなっています。ジャンプ命令やペリフェラル命令で区切る理由については別の回で説明します。
また、ジャンプ命令やペリフェラルアクセスがなく大きな「かたまり」となってしまうのは困るので、「かたまり」には大きさの上限があらかじめ設けられています。
それではこの「かたまり」ついて説明していきます。
TB(Translation Block)とTCG(Tiny Code Generator)
ジャンプ命令を区切りにした各かたまりをQEMUではTranslation Block(略してTB)と呼び、このかたまり(TB)をホストコードに変換する部分をTiny Code Generator(略してTCG)と呼びます。Tiny Code GeneratorはQEMU内部に存在するCの関数です。Tiny Code Generatorの概要について図1を使って説明します。
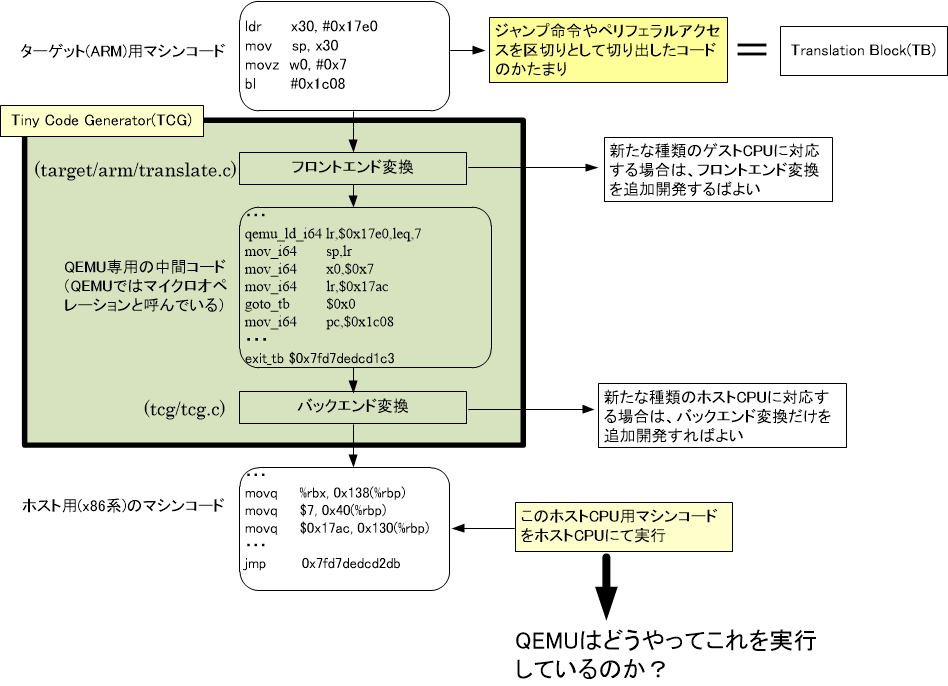
図1にある「ターゲット(ARM)用マシンコード」の部分がTB(Translation Block)に相当します。TB(Translation Block)については後ほどさらに説明します。そして上図の緑部分がTiny Code Generatorです。
図1に示すようにターゲット(ARM)用マシンコードはTCG(Tiny Code Generator)内のフロントエンド変換部分により一旦QEMU専用の中間コードに変換されます。QEMUではこの中間コードをマイクロオペレーションと呼んでいます。ざっくり言えばQEMU用のアセンブリ言語のようなものです。そしてこの中間コードはTCG(Tiny Code Generator)のバックエンド変換部分によりホスト(x86)用のマシンコードに変換されます。
このようにTCGの中をフロントエンド変換とバックエンド変換に分けておくといいことがあります。新しいCPU、例えばRISC-VをゲストCPUとして扱いたい場合は、フロントエンド変換部をRISC-Vに対応できるようにすればいいだけで、バックエンド変換には何も手を加えることなく「RISC-Vからx86」への変換が可能となります。これがフロントエンド変換とバックエンド変換に分かれている理由です。これは当たり前と言えばそれまでなのですが念のため説明しておきました。
問題はバックエンド変換されたホスト(x86)用マシンコードをQEMUはどうやって実行するかです。QEMUは自分自身もx86で動くプログラムなのでx86 CPU内にある各種レジスタを使用しています。そのような状態で、QEMUプログラムとは全く関係のないx86用マシンコードをどうやって実行するのでしょうか。なにも考えずにそのまま実行してしまうとQEMUプログラムが使用しているx86 CPUの各種レジスタの値が書き換わってしまいQEMUプログラムの実行が途中でおかしくなってしまうはずです。
ホスト(x86)コードの実行方法
TCG(Tiny Code Generator)にて生成されたホスト用マシンコードはどのようにQEMU上で実行されるのでしょうか。図2に示したように切り出したTB(Translation Block)に対してフロンドエンド変換後の中間コードとバックエンド変換後のホスト用マシンコードは単純に配列に保存されます。
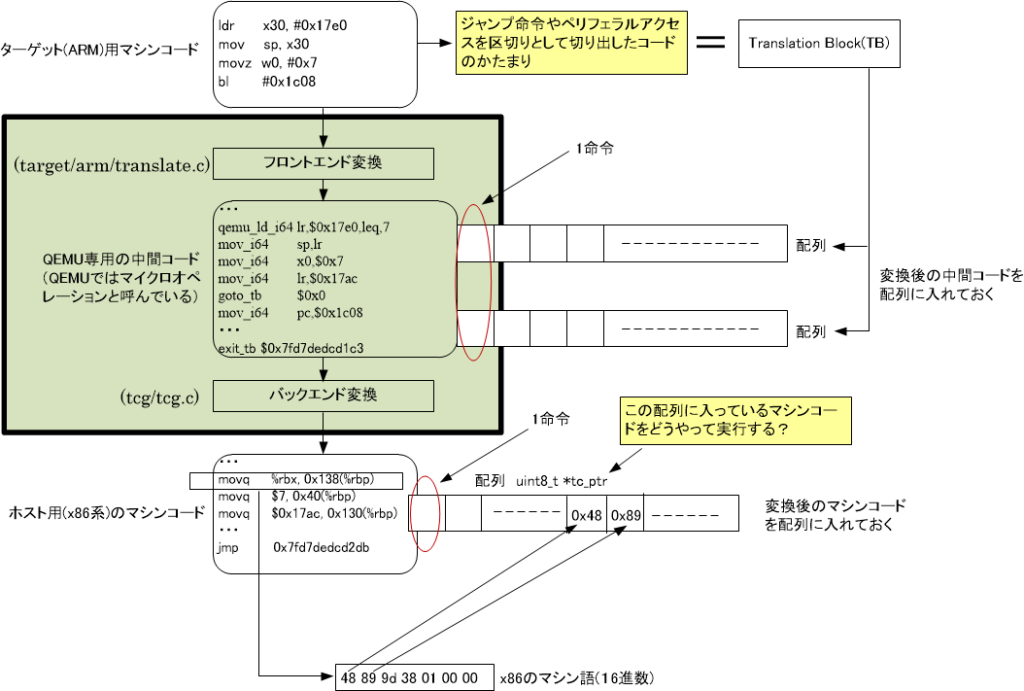
そしてバックエンド変換で生成された配列の中身をつぎのようにしてQEMUは実行しています。かなり複雑ですが一旦図3を表示します。
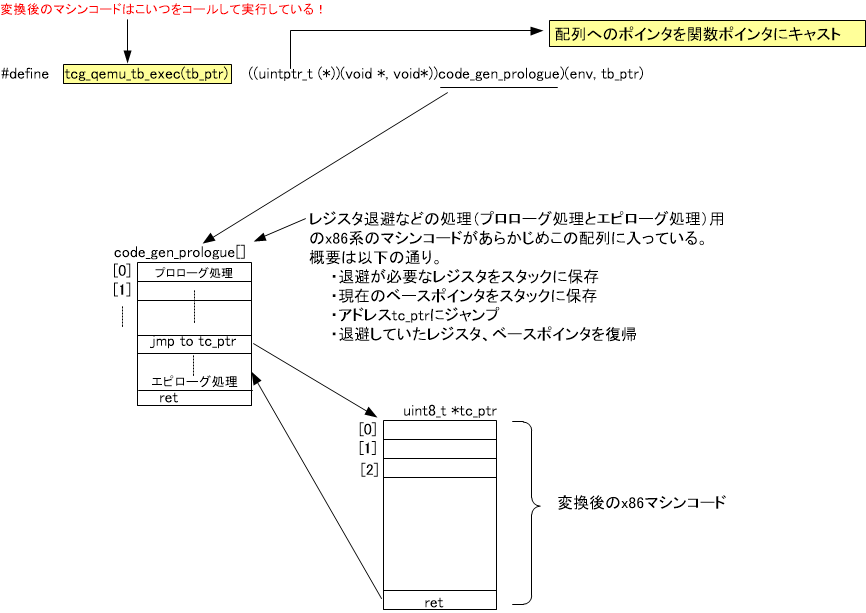
図3で表示されている変数tc_ptrが、TCGのバックエンド変換にて生成されたx86マシンコードを格納した配列です。このマシンコードを実行するために中心的な役割を果たすのが上図に出てくるcode_gen_prologueという配列です。この配列には以下を行うx86のマシン語が事前に格納されています。
- 現在実行中のQEMUが使用しているx86 CPUの各種レジスタの退避(QEMUではこの処理をプロローグと呼んでいる)
- x86のプグラムカウンタを配列tc_ptrの先頭に移動。その後、プログラムカウンタは進みtc_ptr配列の中に書かれているX86のマシン語が実行される。配列の中身を実行できる理由はこの配列が関数ポインタにキャストされているから。
- 変換後のx86マシンコードの実行が終わると退避していたれx86 CPUの各種レジスタの値をメモリからX86 CPU内のレジスタに復帰(QEMUではこの処理をエピローグと呼んでいる)
ただこのcode_gen_prologueという配列はQEMU5.2.0(2020年10月28日)にQEMUソースコードからなくなっており少しアプローチが変わっているようです。しかしQEMUの概念説明としてはこれでよいかと思います。
TB(Translation Block)は再利用
TB情報としては以下のような情報を保持しています。
- TBの先頭命令に対するメモリ上の配置アドレス(ARM CPUでのプログラムカウンタ値)
- 変換後のマシン語(配列tc_ptr)
QEMUがARM CPU命令をx86 CPU命令に変換する際まず最初にやることはプログラムカウンタの値(変換対象となるマシン語が置かれているアドレス)を確認し、過去に変換したことのあるTBがないかについて調べます。あればARM->x86の変換はせずに過去に変換済みのマシン語(TB)を実行します。
TB(Translation Block)の連続実行
ARM CPUのマシン語プログラムをジャンプ命令を区切りとしてTB(Translation Block)に分けるとのですが、ジャンプ命令が少ないために一つのTBが異常に大きくなる場合はどうするのでしょうか。このような場合に備えてQEMUでは事前にTBの最大サイズを決めており、そのサイズを区切りとしてTBを作成します。
ここでまず1つめのTB1を実行する様子を図4に示します。ここでいう実行とは変換後のx86命令の実行を意味します。

このTB1はジャンプ命令で区切られておらずTBの最大サイズで区切られたものとします。
2つめのTB2を実行する様子を図5に示します。
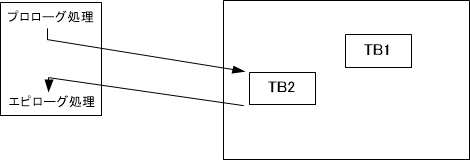
このときTB1とTB2の間にはジャンプ命令(条件分岐)はありません。そこでQEMU内部では図6のようにTB1とTB2をリンク構造として覚えておきます。
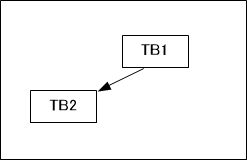
その後再度TB1を実行する場合は図7に示したように、すでに変換済みのTB1を実行し、さらに連続してTB2も実行します。このTB1、TB2の連続実行時にはマシン変換作業は発生しません。なお、TB1を再度使っていい理由はTB1内にジャンプ命令がないからです。もしTB1内にジャンプ命令があったとしたら今回は前回とは違う動作をする可能性があり前回変換結果は使えません。TBをジャンプ命令単位で区切る理由はここにあります。
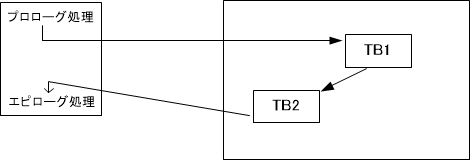
ここで疑問に思うのは「前回は確かにTB1、TB2と連続で実行されたが、今回はTB1の後は別の命令が実行される可能性があるので?」という点です。しかしTB1にはジャンプ命令がないためTB1の後には必ずTB2の内容が実行されることになります。
TB連続実行も困りもの
先述のTB連続実行はマシン語の無駄な変換がなくなりいいのですが、1つ困ったことが発生します。QEMUはマシン語変換だけでなくペリフェラル(UARTなどの周辺回路)のCモデル評価(割り込みチェックなど)も行う必要があります。しかしいつまでもTB連続実行を続けているとその機会を失ってしまいます。
そこでQEMUでは以下のいずれかの方法でマシン語変換作業を中断しペリフェラルのCモデルを処理(割り込みチェックなど)を行うようになっています。
- ホスト側でSIGNAL(LinuxのSIGNAL)を1msごとに発生させマシン語変換作業を中断しペリフェラルのCモデルを処理(割り込みチェックなど)
- QEMUの-countオプション(後述)を使用する場合は、変換命令数がMAX値に達したらマシン語変換作業を中断しペリフェラルのCモデルを処理(割り込みチェックなど)
どんな命令でも中間コードで表現できる?:helper関数
どのようなARM CPU用のマシン語でも中間コード(QEMU専用のマシン語)に変換できるというわけではありません。中間コードに変換できない場合はCの関数を作成しておくことになります。これはQEMUソースコードの中であらかじめ関数として作成します。
このような関数をQEMUではヘルパー(helper)関数と呼んでいます。中間コード中ではこのヘルパー関数をコールすることになっています。
ところでARM CPU内のレジスタ管理は?
変換後のx86コードを実行するときにプロローグ処理においてx86 CPUの各種レジスタの値を退避する、という話をしました。
一方、ARM CPU内の各レジスタ等の値はQEMUのCソースコード内において以下のような構造体を使って管理されています。
typedef struct CPUARMState {
/* Regs for current mode. */
uint32_t regs[16];
/* 32/64 switch only happens when taking and returning from
* exceptions so the overlap semantics are taken care of then
* instead of having a complicated union.
*/
/* Regs for A64 mode. */
uint64_t xregs[32];
uint64_t pc;
/* PSTATE isn't an architectural register for ARMv8. However, it is
* convenient for us to assemble the underlying state into a 32 bit format
* identical to the architectural format used for the SPSR. (This is also
* what the Linux kernel's 'pstate' field in signal handlers and KVM's
* 'pstate' register are.) Of the PSTATE bits:
* NZCV are kept in the split out env->CF/VF/NF/ZF, (which have the same
* semantics as for AArch32, as described in the comments on each field)
* nRW (also known as M[4]) is kept, inverted, in env->aarch64
* DAIF (exception masks) are kept in env->daif
* BTYPE is kept in env->btype
* all other bits are stored in their correct places in env->pstate
*/
uint32_t pstate;
uint32_t aarch64; /* 1 if CPU is in aarch64 state; inverse of PSTATE.nRW */
/* Cached TBFLAGS state. See below for which bits are included. */
uint32_t hflags;
/* Frequently accessed CPSR bits are stored separately for efficiency.
This contains all the other bits. Use cpsr_{read,write} to access
the whole CPSR. */
uint32_t uncached_cpsr;
uint32_t spsr;
/* Banked registers. */
uint64_t banked_spsr[8];
uint32_t banked_r13[8];
・・・次回
今回(第2回)はQEMUのマシン語変換および変換後のマシン語実行について説明しました。これでQEMUとは何か、そしてQEMUの中でどのようなことが実行されているかについてなんとなくわかった気にはなって頂けたのではないでしょうか。
次回(第3回)はQEMUのペリフェラルモデルについて説明します。
